
从去年调转到现在,做了一段时间的云原生,我突发奇想,想发表几个爆论来论述下我眼中的云原生来作为今年最后一篇技术博客。本文纯属个人向吐槽,与本人公司立场无关
概述
云原生大概在 2014-2015 年开始左右,开始正式的提出了这个概念。2015 年 Google 主导成立了云原生计算基金会(Cloud Native Computing Foundation aka CNCF)。在 2018 年,CNCF 在 CNCF Cloud Native Definition v1.01 首次对云原生的概念有了一个认定
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
其中文翻译如下:
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
从官方的定义来看,我更愿意将其称为一个愿景(vision/landscape)而不是一个定义(definition),因为在上述的表达中,并没有清晰明确的表述出云原生这一新生概念的具体的范围与边界,也没有阐述清楚 Cloud Native 和 Non-Cloud Native 之间的差异。
如果以个人的视角来看,一个云原生应用具备以下特质
- 容器化
- 服务化
而一个践行云原生的组织,那么应该具备以下特质
重度 Kubernetes 或其余容器调度平台(如 Shopee 自研的 eru22
具备完整的监控体系
具备完整的 CI/CD 体系
在这个基础上,最近看到很多人都在讨论云原生这一新生概念,所以我想在这里聊聊个人向的四个爆论(爆论中的数据是个人主观判断,轻喷)
- 百分之95以上的公司,没有完成 CI/CD 体系的建立。也没有完成线上服务进程的收敛
- 百分之90以上的公司,没有能微服务化的技术储备
- 百分之90以上的公司,没有能撑起容器化的技术储备
开始爆论
1. 百分之95以上的公司,没有完成 CI/CD 体系的建立。也没有完成线上服务进程的收敛
CI 指持续集成(Continuous Integration aka CI),而 CD 指持续交付(Continuous Delivery aka CD),通常来讲 CI 与 CD 的定义如下(此处引用 Brent Laster 在 What is CI/CD?3 中给出的定义
Continuous integration (CI) is the process of automatically detecting, pulling, building, and (in most cases) doing unit testing as source code is changed for a product. CI is the activity that starts the pipeline (although certain pre-validations—often called “pre-flight checks”—are sometimes incorporated ahead of CI).
The goal of CI is to quickly make sure a new change from a developer is “good” and suitable for further use in the code base.
Continuous deployment (CD) refers to the idea of being able to automatically take a release of code that has come out of the CD pipeline and make it available for end users. Depending on the way the code is “installed” by users, that may mean automatically deploying something in a cloud, making an update available (such as for an app on a phone), updating a website, or simply updating the list of available releases.
通常在我们的实践中,CI 和 CD 的边界并不明显。以常见的基于 Jenkins 的实践为例,我们通常的一套路径是
创建一个 Jenkins 的项目,设定一个 Pipeline(其中包含代码拉取,构建,单元测试等 task),设置触发条件
当指定代码仓库存在主分支代码合入等操作时,执行 Pipeline ,然后生成产物
在生成产物后的,常见有两种做法
在生成产物的下一个阶段触发自动的 deploy 流程,按照 deploy script 直接将生成的产物/镜像直接部署到目标服务器上
将生成的产物上传到中间平台,由人通过部署平台手动触发部署任务
在上面描述的过程中,如果有着完备的流程的公司还会有着其余的辅助流程(如 PR/MR 时的 CI 流程,CR 流程等)
而在面对目标平台的部署时,我自己的另外一个观点是大部分的公司没有完成线上服务进程的收敛。讲个笑话:
Q: 你们怎么部署线上服务呀?A;nohup,tmux,screen
对于当下而言,一个规范化的 CI/CD 流程,收口的线上的服务进程的管理,至少在当下,有着可以遇见的几个好处
尽可能的降低人为手动变更带来的风险
能够较好的完成基础运行依赖配置的收口
依托目前主流的开源的 systemd, supervisor, pm2 等进程管理工具,能对进程提供基础的 HA 的保证(包括进程探活,进程重拉等)
为后续的服务化,容器化等步骤打下基础
2. 百分之90以上的公司,没有能微服务化的技术储备
如果说,对于爆论1 提到的 CI/CD 等手段,我更多的觉得这是一个制度障碍大于技术障碍的现实。那么接下来的几个爆论,我更愿意用没有技术储备来形容
先来说说爆论2: 百分之90以上的公司,没有能微服务化的技术储备
首先来聊聊微服务的概念吧,微服务实际上在计算机历史上有着不同的论述,在2014年 Martin Fowler 和 James Lewis 正式在 Microservices a definition of this new architectural term4 一文中正式的提出了微服务(Microservice)这一概念。
此处引用维基百科的一段概述
微服务是由以单一应用程序构成的小服务,自己拥有自己的行程与轻量化处理,服务依业务功能设计,以全自动的方式部署,与其他服务使用HTTP API通信。同时服务会使用最小的规模的集中管理 (例如 Docker) 能力,服务可以用不同的编程语言与数据库等组件实现
那么我们来用研发的话来尝试描述下关于微服务和与之对应的传统单体服务(Monolith) 之间显著性的差异
微服务的 scope 更小,其更多的专注在某一个功能,或者某一类的功能上
由于其 scope 更小的特性,其变更,crash 所带来的影响相较于传统的单体来说更小
对于多语言多技术栈团队来说更为友好
”符合“现在互联网所需求的小步快跑,快速迭代的大目标
那么我们这里需要思考一下,微服务这一套体系,如果我们想要去进行落地和实践,那么我们需要怎么样的技术储备?我觉得主要是两个方面,架构和治理
首先来聊聊架构吧,我觉得对于微服务来说,最麻烦的一个问题在于从传统单体应用上进行拆分(当然要是最开始创始之初就开始搞微服务的当我没说,虽然这样也有其余的问题)
如前面所说,微服务相较于传统的单体应用来说,,其 scope 更小,更专注在某一个功能或者某一类的功能上。那么这里所引申出来我觉得做微服务最大的一个问题在于合理的划分功能边界并进行拆分
如果拆分不合理那么将导致服务之间相互耦合,比如我将用户鉴权放置在商城服务中,导致我论坛服务需要依赖其不需要的商城服务。如果拆分的过细,那么将导致出现一个很有趣的现象,一个规模不大的业务拆了100多个服务 repo 出来(我们把这种情况称为: 微服务难民2333)
我们践行落地微服务这一套理念,是因为我们在业务和团队规模扩大后,面对多样化的需求与团队成员技术栈时,传统单体应用在其持续维护上的成本将会是一个不小的开支。我们希望引入微服务来尽可能减少维护成本,降低风险。但是不合理的拆分,将会重新让我们的维护成本远超继续践行单体化的方案
而我觉得阻碍微服务继续践行的另外一个问题是治理问题。我们来看一下在微服务化后我们所面临的几个问题
可观测性的问题。如前面所说,微服务化后的单个服务 scope 更小,更多的专注在某一个功能或者某一类功能上。那么这可能导致的问题是,我们在完成一个业务请求所需要经历的请求链路更长。那么按照通用的观点来看,链路更长,其风险更大。那么在在当服务存在异常时(比如业务 RT 的突然增高)我们怎么样去定位具体服务的问题?
配置框架的收口。在微服务化的场景中,我们可能会选择将一些基础的功能下沉至具体的内部框架中(如服务注册,发现,路由等),那么意味着我们需要维护自己的框架,同时完成配置的收敛
老生常谈的服务治理(注册、发现、熔断)等
由于微服务化后,对于一个完备 CI/CD 机制的需求将变得更为迫切。那么如果存在爆论1的情况,将会成为践行微服务这一理念的障碍
诚然,目前无论开源社区(如 Spring Cloud,Go—Micro 等)还是四大云厂商(AWS,Azure,阿里云,GCP)都在尝试提供一种开箱即用的微服务方案,但是除了没法很好的解决如上面所说的诸如架构这样的问题外,其也存在自己的问题
无论是依赖开源社区的方案,还是云厂商的方案,都需要使用者具备一定的技术素养,来定位特定情况下框架中的问题
Vendor Lock-in,目前开箱即用的微服务方案并没有一个通用的开源事实标准。那么依赖某一个开源社区或者云厂商的方案将存在 vendor lock-in 的问题
无论是开源社区的方案还是云厂商的方案,都存在多语言不友好的问题(大家貌似现在都喜欢 Java 一点(Python 没人权.jpg
所以爆论2想表明的一个最核心的观点就是:微服务化并不是一个无代价的行为,与之相反的是一个需要不低技术储备与人力投入的的行为。所以请不要认为微服务是万能良药。请按需使用
3. 百分之90以上的公司,没有能撑起容器化的技术储备
目前很主流的一个观点,是能上容器尽可能上容器,说实话这个想法实际上是有一定的合理性的,去 review 这个想法,我们需要去看一下容器这个东西,给我们带来了什么样的改变
容器首先毫无疑问,会给我们带来非常多的好处:
- 真正意义上让开发与生产环境保持一致是一种非常方便的事,换句话说,开发说的“这个服务在我本地没啥问题”是一句有用的话了
- 让部署一些服务变的更为方便,无论是分发,还是部署,
- 能做到一定程度上的资源隔离与分配
那么,看起来我们是不是可以无脑用容器?不,不是,我们需要再来 Review 一下,容器化后我们可能所要面临的一些弊端:
- 容器安全性问题,目前最主流的容器实现(此处点名 Docker)本质上而言还是基于 CGroups + NS 来进行资源与进程隔离。那么其安全性将会是一个非常值得考量的问题。毕竟 Docker 越权与逃逸漏洞年年有,年年新。那么这意味着我们是需要去有一个系统的机制去规范我们容器的使用,来保证相关的越权点能被把控在一个可控的范围内。而另一个方向是镜像安全问题,大家都是面向百度/CSDN/Google/Stackoverflow 编(fu)程(zhi)选手,那么势必会出现一个情况,当我们遇到一个问题,搜索一番,直接复制点 Dockerfile 下来,这个时候,将会存在很大的风险点,毕竟谁也不知道 base image 里加了啥料不是?
- 容器的网络问题。当我们启动若干个镜像后,那么容器之间的网络互通怎么处理?而大家生产环境,肯定不止一个机器那么少,那么跨主机的情况下,怎么样去进行容器间的通信,同时保证网络的稳定性?
- 容器的调度与运维的问题,当我一个机器高负载的时候,怎么样去将该机器上的一些容器调度到其余的机器上?而怎么样去探知一个容器是否存活?如果一个容器 crash 了,怎么样重新拉起?
- 容器具体的细节问题,比如镜像怎么样构建与打包?怎么样上传?(又回到了爆论1)乃至说怎么样去排查一些 corner case 的问题?
- 对于一些特定的 large size 的镜像(如机器学习同学常用的 CUDA 官方镜像,打包了字典模型等大量数据的镜像等)怎么样去快速下载,快速发布?
可能这里又会有一种观点,没事,我们上 Kubernetes 就好啦,上面这些很多问题就能解决啦!好吧,我们再来聊聊这个问题
首先我已经忽略掉自建 Kubernetes 集群的场景了,因为那不是一般人能 Hold 住的。那么我们来看一下,依托公有云使用的情况吧,以阿里云为例,点开页面,然后我们见到这样张图
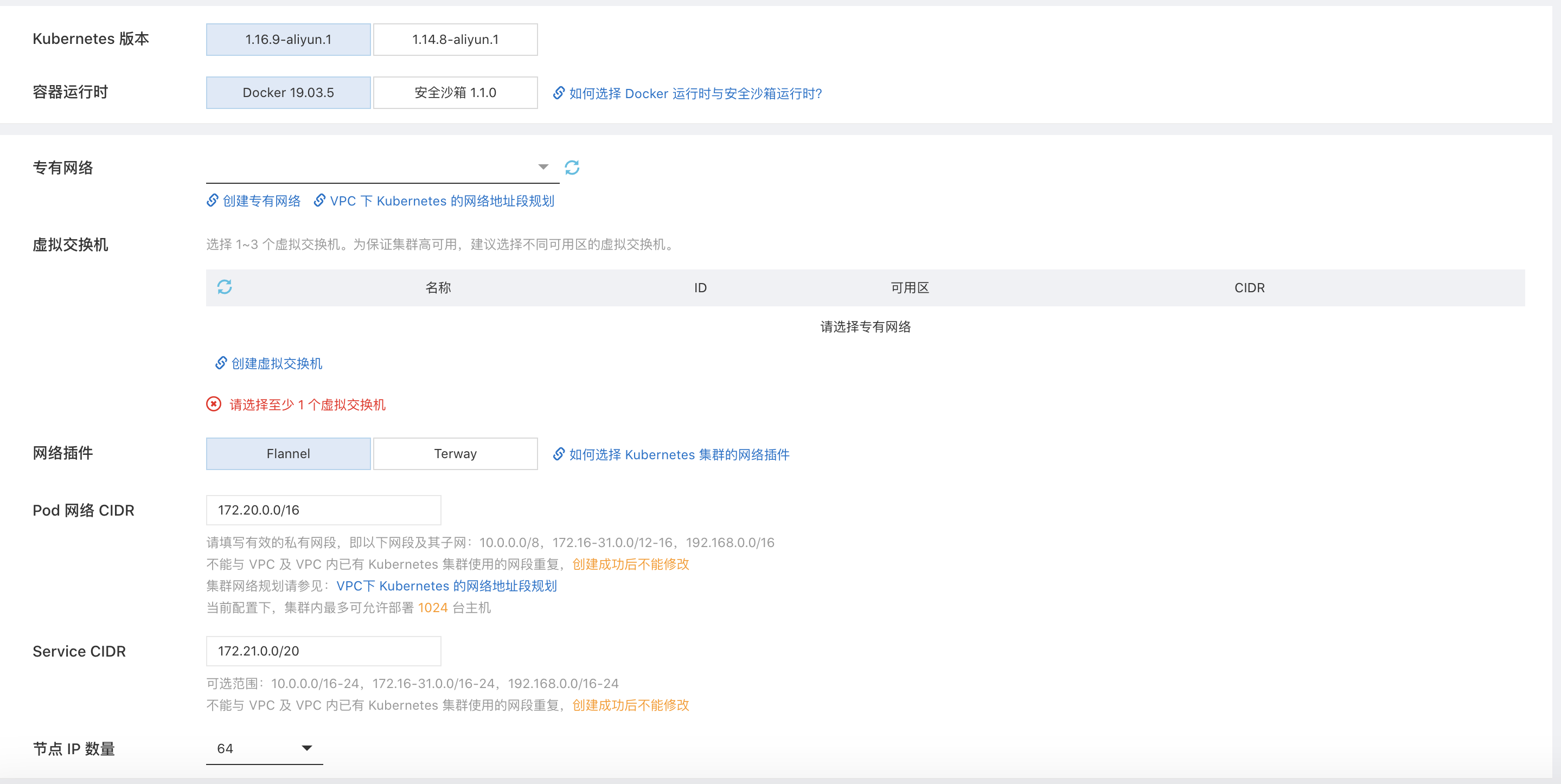
好了,提问:
- VPC 是什么?
- Kubernetes 1.16.9 和 1.14.8 有什么区别
- Docker 19.03.5 和阿里云安全沙箱 1.1.0 是什么,有什么区别
- 专有网络是什么?
- 虚拟交换机是什么?
- 网络插件是什么?Flannel 和 Terway 又是什么?有什么区别?当你翻了翻文档,然后文档告诉你,Terway 是阿里云基于 Calico 魔改的 CNI 插件。那么 CNI 插件是什么?Calico 是什么?
- Pod CIDR 是什么怎么设?
- Service CIDR 是什么怎么设?
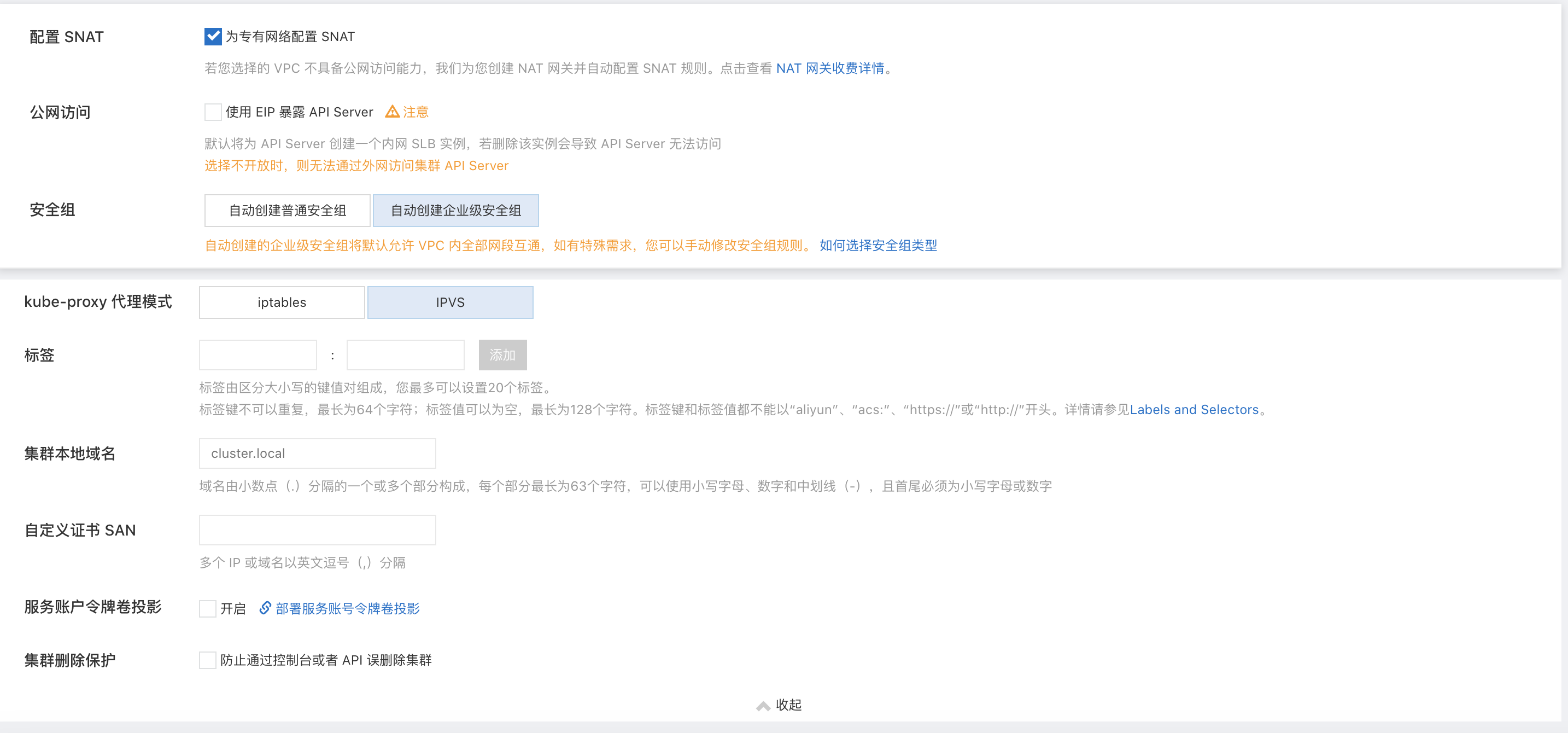
- SNAT 是什么怎么设?
- 安全组怎么配置?
- Kube-Proxy 是什么?iptables 和 IPVS 有什么区别?怎么选?
大家能看到上面的问题涵盖了这样几方面
Kubernetes 本身的深入了解(CNI,runtime,kube-proxy 等)
一个合理网络规划
对于云厂商特定功能的熟悉
在我看来,这三方面任何一方面对于一个技术团队的技术储备以及对于业务的理解(广义的技术储备)都需要有一个不浅的需求。
当然这里在碎碎念一下,实际上搞 Kubernetes 这一套开销实际上很大的(有点偏题,但是还是继续说吧)
- 你得有个镜像仓库吧,不贵,中国区基础版780一个月
- 你集群内的服务需要暴露出去用吧?行叭,买个最低规格的 SLB,简约型,每个月200
- 好了,你每个月日志得花钱吧?假设你每个月20G日志,不多吧?行,39.1
- 你集群监控要不要?好,买,每天50w条日志上报吧?行,不贵,975 一个月
算一下,一个集群吧,(780+200+39.1+975)*12=23292.2一年,不算集群基础的 ENI,ECS 等费用,美滋滋
而且 Kubernetes 会有很多的玄学的问题,也需要技术团队有足够的技术储备来进行排查(我想想啊,我遇到过 CNI 一号进程 crash 了没重拉,特定版本上的内核 cgroup 泄漏,ingress OOM 等问题),大家可以去 Kubernetes 的 Issue 区看一下盛况(说多了都是泪)
总结
我知道这篇文章写出来会存在很多的争议。但是我始终想表述的一个观点是对于云原生时代这一套东西(实际上也更多是之前传统技术的延伸),他们的引入并不是无代价,并不是无成本的。对于有着足够规模与痛点的公司来说,这样的成本对于他们的业务增长来说是一个正向的促进,而对于更多中小企业来说,可能这一套对于业务的提升将会是非常小乃至说是负作用。
我希望我们技术人员在做技术决策的时候,一定是在评估自己的团队的技术储备乃至对于业务的收益后再引入某一种技术与理念,而不是引入一个技术只是因为它看起来够先进,够屌,能够为我的简历背书
最后用之前我分享过的一句话来作为本文的结尾吧
一个企业奔着技术先进性去搞技术,就是死






