
好久没博客了,来写个简单的读论文笔记吧,这篇文章是来自 Google 2016 年发表的一篇论文 Maglev: A Fast and Reliable Software Network Load Balancer 分享了他们内部从08年开始大规模使用的软负载均衡系统的实现。里面很多很有趣的细节,我看我能写多少,算多少吧
背景
负载均衡的概念大家肯定都比较熟悉了,再次不再赘述。现在我们需要考虑 Google 的场景。设计之初,Google 需要一种高性能的 LB 来承担 Google 一些重头服务的流量,比如 Google 搜索,Gmail 等等。由于流量非常庞大,那么 LB 需要非常强大的性能来处理大量的流量。
在这里,传统的想法可能说,我直接上专业的硬件负载均衡,能用钱解决的问题,都不算事(笑。但是这样的方案有着不小的问题
- 硬件负载均衡单点的性能决定了整个网络能承担的请求
- 在 HA 上存在缺陷。为了保证单点失效的时候,整个网络集群不陷入瘫痪。那么我们通常需要 1:1 的做冗余
- 灵活性和编程性欠缺,想做骚操作的时候没有切入点
- 太贵了。贵到 Google 都承受不了(逃
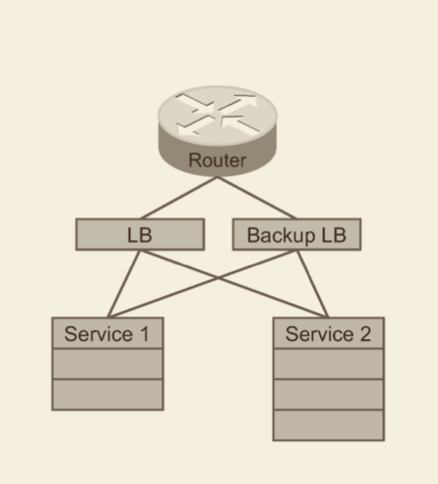
在这样一种情况下,Google 开始考虑自行构建一种 SLB (Software Load Balance) 系统。去构建这样一种系统。好处也很明显。比如方便的 Scale ,为了保证 HA 所需的冗余从之前的 1:1 可以降至 N+1 ,方便的定制性等。架构就演变成下图了

但是挑战也很明显。首先需要有足够的性能,这样保证集群有足够的吞吐。同时需要做 connection tracking ,这样保证同一个连接的数据包能妥投到同一个机器上。也许要保证能有透明的 failover 的能力。
这样一些要件结合起来,这也就是我们今天要聊的 Maglev。Google 从 08 年开始大规模的应用的 LB 系统
Maglev 初窥
背景知识
在继续聊 Maglev 之前,我们需要去了解 Google 现在怎么样去去使用 Maglev 的,下面是一个简化后的示意图
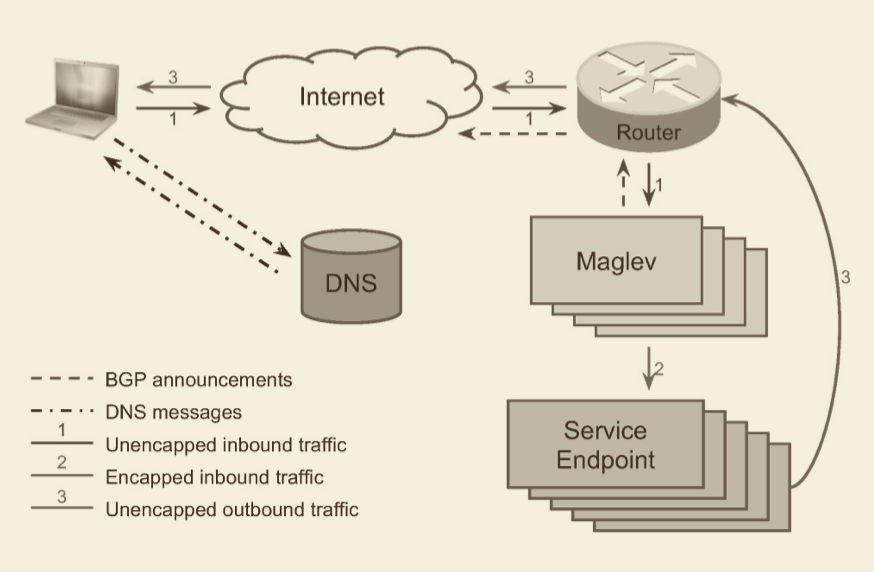
同时这里我们需要介绍一个很重要的概念叫做 VIP(Virtual IP Address) 。 用过 Kubernetes 的同学肯定对这个概念并不陌生。VIP 并不是一个实际与网卡绑定的物理 IP。近似来讲它可以作为后端一组 Endpoint 的抽象,当你访问这个 VIP 的时候,实际上是在访问后端的 Endpoint 。这里举个更方便理解的例子,以 Kubernetes 为例,我们在创建完一组 Pod 后,为了暴露 Pod 中提供的服务,我们通常会创建一个 Service 来关联对应的 Pod。Service 通常会有一个 IP,那么这个 IP 就是一个 VIP 。当我们访问 Service 的 IP 的时候,通常会随机从后面的 Pod 中选择一个承接请求。
好了,回到 Maglev ,我们现在来看下整个的一个流程。Maglev 会和 VIP 关联,然后将 VIP 透传给一组 Router。 当用户在浏览器中输入 https://www.google.com 并按下回车的时候,浏览器会进行 DNS 解析。而 DNS 解析将由 Google 的 DNS 服务器进行处理。DNS 服务器会根据用户的区域选择一个最近集群的 VIP 返回给用户,然后浏览器会根据获取到的 VIP 建立连接。
当 Router 收到对应包时,会将包转发给 VIP 所属的 Maglev 集群中的任意节点。集群中的每个节点权重都是平衡。Maglev 节点在接受到包的时候,会利用 GRE(Generic Routing Encapsulation) 进行封包。然后传输给对应的后端端点。
当后端端点接收到数据包的时候,会进行接包并处理请求。当响应数据准备就绪的时候,会进行封包操作,会将 VIP 的作为源地址,用户的 IP 作为目标地址,然后响应数据作为数据包操作。这个时候,后端端点会利用 DSR(Direct Server Return) 将数据包绕过 Maglev 直接返回。这样避免响应过大的时候对 Maglev 造成额外的负担。实际上 DSR 在 L4 的 LB 实现,如 HAProxy,Envoy 等都得到了比较多的应用。改天有时间写篇博客来聊聊。
Maglev 配置
如前面所说, Maglev 接收来自 Router 的 VIP 请求,然后将对应流量转发到对应的后端端点上。每个 Maglev 将由 Controller 和 Forwarder 组成,其架构如下所示

而 Controller 和 Forwarder 都利用 Configuration Object 管理相关 VIP。Configuration Object 这一套实际上又是另外一套系统(可以近似的认为是注册中心),彼此之间通过 RPC 来通信。
在 Maglev 机器上,Controller 会定期对 Forwarder 进行检查。根据检查结果来确定是否通过 BGP 提交/撤回所有 VIP 的注册(要么全部成功,要么全部失败,其实还是为了保障系统的一致性)。这样确保从 Router 过来的流量都能扔到健康的机器上
而从 Router 过来的 VIP 流量将会由 Forwarder 进行处理。在 Forwarder 中,每个 VIP 都会和一个或多个 backend pool 关联。除非特殊处理,Maglev 中的 backend 都是服务端点。一个 backend pool 可以包含一组服务端点的的物理 IP ,也可以是其余的 backend pool。每个 backend pool 都会根据其特定需求,设计若干个监控检查器,数据包只会转发给健康的服务。如之前所说,同一个服务可能会被包含在多个 backend pool 中,因此 Forwarder 将会根据具体的地址进行去重,避免额外的开销。
Forwarder 的 Config Manager 将负责从 Configuration Object 中拉取,解析并验证相关的配置。所有配置的提交都是具备原子性(要么全部成功,要么全部失败)。在推送和解析到生效的过程中,存在一个非常短暂的 gap,在此期间,一个 Maglev 集群之间的配置可能存在不同步的情况。不过因为一致性 Hash 的存在,在这个非常短的 Gap 内,大部分请求还是能成功妥投。
Maglev 实现
好了,扯了这么多,来看一下 Maglev 整个系统的一些实践细节
概述
总所周知(如前面所说),Maglev 由 Forwarder 来实际承担流量相关的转发工作,我们用一张图来说明一下它的结构

Forwarder 将直接从 NIC(Network Interface Card) 拿到数据包,然后直接扔入 NIC 转发到后端。期间所有操作都不会过内核(实际上过内核会有额外的 cost)
从 NIC 中捞出的包,会先由 Steering Module 进行处理,在处理过程中,Steering Module 将会根据五元组(协议,目标地址,目标端口,源地址,源端口)进行 hash 计算。然后将其转入对应的 Receiving Queue 中。每个 Receiving Queue 都会对应一个处理线程。处理线程将过滤掉目标 VIP 和本机注册 VIP 不匹配的包。然后会重新计算五元组 hash,然后从 Connection Tracking Table 中查找对应的值。
在 Connection Tracking Table 中存放之前五元组 Hash 所对应的 Backend,然后如果查找命中,那么直接复用,如果未命中,则为这个包选择一个新的 Backend, 然后将键值对加入 Connection Tracking Table。如果此时没有 Backend 可用,那么这个包会被丢弃。当这个包完成查找操作后,如前面所说,会改写这个包,然后将其放入 transmission queue 中去。最后将 muxing module 会将 transmission queue 的包直接通过 NIC 发送出去。
这里有个问题,在 Steering Module 中为啥不考虑根据 round-robin 这种常见的策略来做?大家都知道每个线程的处理速度是不一致的,如果直接裸 round-robin ,那么面对这种情况,可能会导致数据包重排的情况发生,如果是引入权重的概念来改良,又会引入新的复杂度,毕竟线程的处理速度是动态变化的。另外一种是 connnection tracking 的情况,假设我们有个需要持久化的连接,我们需要保证每个包都能扔到同样的机器上,这个时候用 round-robin 就会引入额外的复杂性。不过对于一些特殊情况,比如 receive queue 满了,一致性 Hash 处理不过来的时候,我们会利用 round-robin 作为 backup 的手段来替代一致性 Hash,这种情况对于同时存在同样5元组包的时候比较好用。
高效处理数据包
前面已经花了很多时间讲述了,Maglev 是直接对 TCP 的数据包进行操作,同时因为 Google 的流量极为庞大,那么这个时候实际上是需要 Maglev 有着良好的转发性能。不然在大规模场景下,其吞吐能力会无法满足需求。Google 怎么做的?答:直接对网卡操作。。
我们都知道在 Linux 中进行网络编程的时候,将数据包从内核态拷贝到用户态实际上是一件开销非常大的事,所以对于一些极端需求性能的场景,如 L4 的负载均衡等,大家可能更倾向于将东西做到内核里,避免跨态拷贝。这也是 LVS 等工具的思路。但是实际上对于更大规模的流量,来讲,从网卡到内核,经过内核中的一堆 filter 处理也是一件开销非常大的事,而如同前面所说,Maglev 只依赖数据包中的五元组,对于包序列号,包 payload ,都不需要关心。于是 Google:我有一个大胆的想法!好了,来看张图

Google 选择直接在 NIC (即网卡) 上进行编程。让 Forwarder 和 NIC 共享一片内存。内存中维护的是一个环状的数据包池子。然后 Forwarder 中的 steering module 和 muxing module 各自维护三个指针来处理这些数据包,下面详细描述一下
首先而言 steering module 维护了三个指针
received,管理接收数据包reserved, 管理已接收未处理的数据包processed, 管理处理完成的数据包
那么流程是这样的,当 NIC 接受到新的数据包后,那么 received 指针指向的内存会被修改。然后当一个数据包被分发给线程完成相关操作后,那么 processed 指针指向的内存地址会被修改。因为是个环状结构嘛, received 和 processed 中间存在的数据包就是已接收但未完成处理的包,由 reserved 指针进行管理。
于此对应的,muxing module 也维护了三个指针
sent,管理已发送完毕的数据包ready,管理已经就绪等待发送的数据包recycled, 管理已回收的数据包
那么对应的流程是这样的,当 steering module 完成相关包的处理的时候,ready 指针指向的内存会被修改,然后等待发送。当一个数据包发送后,sent 指向的内存地址被修改。在 ready 和 sent 之外有另一个状态 recycled 管理已经回收的数据包。
我们可以看到在这个过程中,没有发生数据拷贝的操作,实际上这减小了一部分复制数据带来的时延。不过这种方法存在的问题就是,当指针越界后,会带来很大的额外开销。所以 Google 采用的做法是批处理,比如接收 3000 个小包集中处理一次,这样的骚操作
另外需要做一些额外的优化,比如包处理线程之间不共享数据以避免竞态。比如需要将线程与具体 CPU Core 绑定来保证性能等等
目前来看,Google 这一套的做法效率非常的出色,平均每个包的处理只需要 300 ns($10^{-9}$s)。如同前面所说,Google 采用批处理的方式来处理包,这样的问题是每当一些例如硬件中断的情况发生的时候,可能到达处理阈值的时间会比大部分情况长很多,所以 Google 设计了一个 50μs($10^{-6}$s) 的 Timer 来处理这种情况。换句话说,当因为硬件或者其余问题时,整体的包处理时长可能会增加 50μs 的时间(其实这里感觉 Google 怎么是在得瑟,你看我们性能超棒的噢,只有硬件是我们的瓶颈喔(逃
后端选择
如同前面所说的一样,Forwarder 会为数据包选择一个后端。对于 TCP 这种常见来说,将相同五元组的数据包转发到同一个后端节点上非常重要。Google 采取在 Maglev 中维护一个 connction tracking table 来解决这个问题。当一个包抵达的时候,Maglev 会计算其五元组 Hash ,然后确定在 table 中是否存在,如果不存在,则选择一个节点作为后端,然后将记录值添加到 table 中。如果存在则直接复用
这样看起来没有问题了对吧?Google:不,不是,还有问题!
我们首先考虑这样一种场景:如前面所说,Maglev 前面挂了一个/组 Router,而 Router 是不提供连接亲和的,即不保证把同一个连接的包发送到同一个机器上。所以可能存在的情况是同一个连接的不同数据包会被仍在不同的机器上。再比如,我们假设 Router 是具有连接亲和的,但是也会存在如果机器发生重启后,connection tracking table 被清空的情况。
再来一个例子,我们都知道 connection tracking table 它所能使用的内存,必定是有一个阈值的。这样在面对一些流量非常大,或者 SYN Flood 这种非正常情景的时候。当 connection tracking table 的容量到达阈值的时候,我们势必会清理一些数据。那么在这个时候,一个连接的 tracking 信息就很有可能被清理。那么在这种情况下,我们怎么样去做 connection tracking ?
Google 选择的做法是引入一致性 Hash
一致性 Hash:Maglev Hash
整体算法其实有很多细节,这里只说明大概,具体细节大家可以去阅读原文查找
首先,我们要确定经过预处理后的产物 lookup table 的长度 M。所有 Key 都会被 hash 到这个 lookup table 中去,而 lookup table 中的每个元素都会被映射到一个 Node 上
而计算 lookup table 的计算分为两步
- 计算每一个 node 对于每一个 lookup table 项的一个取值(也就是原文中提到的 permutation);
- 根据这个值,去计算每一个 lookup table 项所映射到的 node(放在 entry 中,此处 entry 用原文的话来讲就是叫做
the final lookup table)。
permutation 是一个 M×N 的矩阵,列对应 lookup table,行对应 node。 为了计算 permutation,需要挑选两个 hash 算法,分别计算两个值 offset 与 skip 。最后根据 offset 和 skip 的值来填充 permutation,计算方式描述如下:
- offset ← h 1 (name[i]) mod M
- skip ← h 2 (name[i]) mod (M − 1)+ 1
- permutation[i][j] ← (offset+ j × skip) mod M
其中 i 是 Node Table 中 Node 的下标,j 是 lookup table 下标
在计算完 permutation 后,我们就可以计算最后的 lookup table 了,这个 table 用一维的数组表示

这里贴一张图,大家可以配合下面的代码一起看一下
1 | from typing import List |
在这里我们能看到,这段循环代码必然结束,而最坏情况下,复杂度会非常高,最坏的情况可能会到 O(M^2)。原文中建议找一个远大于 N 的 M (To avoid this happening we always choose M such that M ≫ N.)可以使平均复杂度维持在 O(MlogM)
而 Maglev 中 Google 自研的一致性算法性能怎么样呢?论文中也做了测试

可以看到,对于不同大小的 lookup table,Maglev 表现出了更好的均衡性
说实话,Maglev 在我看来本质上是一个带虚节点的 Hash,说实话,我没想到为什么 Google 不用 Dynamo 等已经比较成熟的 Hash ?难道是因为政策原因?(毕竟 Dynamo 是 AWS 家的嘛(逃。BTW Enovy 也实现了 Maglev 。参见 Evaluate other consistent hash LB algorithms ,而且引入了权重,实现的挺不错,有兴趣的同学可以去看看(逃
说实话,Maglev Hash 还有很多细节没有讲,不过实在懒得写了,,等后面出一个一致性 Hash 的分析博客吧,Flag++
Maglev 优化
前面我们已经把 Maglev 这一套的基本原理讲的差不多了。但是如果作为一个生产上大规模使用的 LB ,那么势必还需要针对细节做很多优化,由于这里涉及到很多方面,我这里只简单介绍一下,剩下的还是建议大家直接去读原文
分段数据包的处理
熟悉网络的同学都知道,在基于 IP 协议传输报文的时候,受限于 MTU 的大小,在传输的时候,可能会存在数据分片传输的情况,而这些分片后的数据不一定会带有完整的五元组信息。比如一个数据被切分为两段,那么第一段将带有 L3 和 L4 的头部信息,而第二段只带有 L3 的信息。而在传输过程中,因为网络关系,Maglev 无法完全保证对接收到的数据作出正确的处理
这样问题就大了,因为数据分段的情况实际上是非常场景的。那么对于这样的场景,Maglev 应该怎么样去处理?首先我们需要确定怎么样才能保证所有数据都能妥投
- 保证一个数据报文的不同数据段都需要由同一个 Maglev 实例处理
- 对于同一个数据报文的不同数据段需要能保证后端选择结果是一致的
OK,那么我们来看看 Google 是怎么解决这个问题的。
首先,每个 Maglev 实例中都会有一个特殊的 backend pool ,池子中是该 Maglev 集群中所有的实例。当接收到数据后,Maglev 会先根据三元组(源地址,目标地址,协议簇)计算 hash ,然后选择一个 Maglev 实例进行转发,这样就能保证同一数据报文的不同分段能传输到同一个 Maglev 实例上。当然这里需要利用 GRE 的递归控制来避免无限循环。
好了我们来看看条件2怎么满足。在每个 Maglev 实例上会维护一个特殊的表,记录数据分片后第一个数据端的转发结果。以前面的例子为例,当一个报文的第二个分段抵达的时候,Maglev 会查询表中是否存在第一个数据段的转发结果。如果存在则直接转发,如果不存在,则将这个数据段缓存,直到第一个数据段抵达,或者到达超时阈值
监控与调试
真正的用时都是不需要调试(划掉)(笑,Google 为了这一套系统设计了辅助的监控与调试手段来帮助日常的开发迭代。
在监控这边,分为黑盒和白盒两种监控手段。比如遍布全球的特定监控节点,以确认 VIP 的健康状态。当然与之配套的还有一整套白盒监控。Google 会监控具体的服务器指标,同时会监控 Maglev 本身的指标
当然与之配套的还有一些调试工具。比如 Google 开发了一套类似 X-Trace 的 packettracer。可以通过 packettracer 来发送一些带有特定标头和 payload 的信息。当 Maglev 接到这样一些特殊的数据包后,除了照常转发数据包以外,也会讲一些关键信息上报到指定位置
这其实也体现了软负载均衡相较于硬件负载均衡的一个好处,无论可调试性还是可迭代性都是硬件负载均衡无法媲美的
总结
这篇文章其实我读了挺久,里面很多细节挺值得慢慢深究的,所以再次建议大家一定要去找原文读一下,非常不错。另外顺便推荐一篇文章,是美团技术团队的作品,他们也参考了 Maglev 来实现自己的高性能 L4 负载均衡,参见MGW——美团点评高性能四层负载均衡
好了,这篇文章,就先到这里吧,这篇文章应该是我写的最耗时的一篇文章了。。不过想想后面还有几篇文章要写,头就很大
溜了溜了






