
过年是个好时候,可以猛猛干活或者看论文。不过上了几天磨,看了几天论文后觉得还是需要整点活
所以这篇文章来聊聊一个经典话题,How to trace your SQL?
正文
在 OpenTelementry 这一套开始铺展开来后,我们对于代码整个生命周期的 tracing 有了一个较为成熟的方案。包括各类 auto-instrumentation 的库,能够让我们在不修改代码的情况下就能对整个调用链进行 tracing。
但是始终有一朵乌云盘绕着 Tracing 世界的大厦上,我们怎么样将 SQL 的执行如同业务代码一样从黑盒中拆出来
在现阶段,我们对于整个 Tracing 的引入都是在做加法,我们选择构建一个 context,注入一些 metadata,让代码中不同的环节都可以获取到上下文。但是还是有一个问题,怎么样在 SQL 中做加法呢?
最直观的想法是,我们可以尝试一个类似机制
1 | begin; |
我们可以在 SQL 中设置一些 tracing_id 之类的东西,这样我们就可以在明确一个事务的上下文了。但是这个方案有一个问题,这会改变我们使用 SQL 的 pattern,我们需要在每个 SQL 语句前面都加上 set saka.tracing_id = ‘1234567890’ 这样的东西,这样就会导致我们在代码中需要修改大量的 SQL 语句,这显然是不可行的。
那么另外一种方式实现的我们可以将 tracing 注入到 SQL 中,something like this:
1 | select * from users where id = 1 /* tracing_id: 1234567890 */; |
那么怎么做?
Google 提出了一个通用的方案 or 叫一个事实上的的标准吧,叫作 SQLCommenter,它的核心思想就是通过 Hook ORM 等手段,让我们尽可能简单的在 SQL 中注入一些 comment,这些 comment 中包含了 tracing/Custom Tag 的信息,这样我们可以将元数据注入的成本降到最低。
那么我们来根据 SQLCommenter 的方案来看看我们怎么样在 Python 中实现这个功能,
以 pymysql 为例,我们需要实现这个非常简单
1 | from pymysql.cursors import SSCursor, SSDictCursor |
然后我们在使用时,注入自定义的 Cursor 就好了
Python 的生态还是幸福,但是很可惜,我现在是被迫在写 Node.js 的代码了,Node.js 的生态就没有那么幸福了。由于历史原因,我们现在用的是极为美味的 Prisma 作为 ORM。那么我们需要在 Prisma 来看一下怎么样注入 SQL Comment。
首先在 Prisma 最新的 v7.x 版本中,Prisma 本身实现了 SQLCommenter 的功能,something like this:
1 | import { queryTags, withQueryTags } from "@prisma/sqlcommenter-query-tags"; |
最终会生成类似这样的 SQL
1 | SELECT ... FROM "User" /*requestId='abc-123',route='/api/users'*/ |
OK, 很不错,是预期内行为
但是问题在于 Prisma V7 是一个极为屎一样的版本,我们完全无法如品鉴母鸡卡一样品鉴这个功能。因为性能问题(v7 比 v6 慢了 30%-40%),我们完全无法在生产环境中使用 v7 的版本,所以我们只能在 v6 中实现这个功能了。
在 Prisma v6 中,Prisma 数据映射部分和核心的 Query Engine 是完全分开,他们通过走 NAPI-RS 进行通信,而他们自定义了一套 json based 的传输协议,协议样例如下
1 | { |
而在这一次,我想实现类似官方的语义
1 | return this.prisma.post.findMany({ |
OK,那么我们直接用一个流程图来输出一下对应的实现流程
flowchart TD
subgraph TS["TypeScript (prisma repo)"]
A["用户代码<br/>prisma.user.findMany({sqlComments: {...}, where: {...}})"]
B["getPrismaClient.ts :: _executeRequest()<br/>调用 serializeJsonQuery()"]
C["serializeJsonQuery.ts :: serializeJsonQuery() <b>[改动1]</b><br/>提取 sqlComments 放入 JsonQuery 顶层<br/>输出: {modelName, action, query, sqlComments}"]
D["RequestHandler.ts :: singleLoader / batchLoader<br/>调用 _engine.request(protocolQuery, {traceparent})"]
E["LibraryEngine.ts :: request()<br/>JSON.stringify(query) + JSON.stringify({traceparent})<br/>engine.query(queryStr, headerStr, txId)"]
end
subgraph FFI["C ABI / NAPI FFI 边界"]
F(("FFI"))
end
subgraph Rust["Rust (prisma-engines repo)"]
G["QueryEngine::query()<br/>解析 body_str → RequestBody<br/>从 header 提取 traceparent"]
H["RequestHandler::handle() <b>[改动2]</b><br/>body.into_doc() → (QueryDocument, SqlCommentsVec)<br/>组装 QueryContext {traceparent, sql_comments}"]
I["Single 查询<br/>QueryContext::new(traceparent, sql_comments#0)"]
J["Batch 查询<br/>每个 operation 独立 QueryContext<br/>共享 traceparent,各自 sql_comments"]
K["JsonBody::into_doc() <b>[改动3]</b><br/>JsonSingleQuery 新增 sql_comments 字段<br/>extract_sql_comments() → Vec<(String,String)>"]
L["QueryExecutor::execute() <b>[改动4]</b><br/>traceparent → query_context: QueryContext<br/>管道传递: execute_operation → interpreter → read/write"]
M["interpreter :: read.rs / write.rs <b>[改动5]</b><br/>query_context.sql_trace() → SqlTrace {traceparent, sql_comments}"]
N["ReadOperations / WriteOperations <b>[改动6]</b><br/>traceparent: Option<TraceParent> → trace: SqlTrace"]
O["sql-query-connector :: connection.rs <b>[改动7]</b><br/>Context::new(&connection_info, trace)"]
P["sql-query-builder :: read/write/select <b>[改动8]</b><br/>构建 Quaint AST<br/>调用 .add_trace_id(ctx)"]
Q["sql_trace.rs :: add_trace_id() <b>[改动9]</b><br/>build_trace_comment(sql_comments, traceparent)<br/>1. sql_comments 按 key 字母排序<br/>2. key/value URL 编码, 格式: key='value'<br/>3.
traceparent sampled 则追加<br/>4. 逗号拼接, 调用 .comment(result)"]
R["Quaint AST :: .comment(...)<br/>渲染时在 SQL 末尾追加 /* ... */"]
end
S["最终 SQL<br/>SELECT ... FROM "User" WHERE ...<br/>/* controller='UserController',route='%2Fapi%2Fusers' */"]
A --> B --> C --> D --> E
E --> F --> G --> H
H --> I --> L
H --> J --> L
H -.->|内部调用| K
L --> M --> N --> O --> P --> Q --> R --> SOK,在调整完 FFI ,扩展完 Query Engine 后,我们再调整一下 Prisma 代码生成相关的部分即可
然后我们可以在业务代码中这样使用
1 | function getSqlComments(req: Request): Record<string, string> { |
然后我们可以得到这样的 SQL
1 | 2026-02-22 07:56:38.681 GMT [190] LOG: execute s412381: SELECT "public"."Post"."id", "public"."Post"."title", "public"."Post"."body", "public"."Post"."createdAt", "public"."Post"."modifiedAt" FROM "public"."Post" WHERE ("public"."Post"."id" = $1 AND 1=1) LIMIT $2 OFFSET $3 /* method='GET',route='%2Fposts%2Fff4ccd6d-2c15-4979-a5f3-0c27e4e2f169',route_pattern='%2Fposts%2F:id',traceparent='00-e984180b391935fbdf2b1e1f6f3b2b12-1286ff6754fbbc57-01' */ |
通常来说,这样的语句已经能在我们常见的数据库调试流程中已经起到很大的帮助了,可以查到某一条慢 SQL 的来源,上下文等信息
但是这就够了吗?我们能不能把数据库也接入到 OpenTelemetry 的 tracing 体系中来呢?我们能不能在数据库的层面上看到整个调用链的 tracing 信息呢?
那没有问题的,这里以我现在更熟悉一点的 PostgreSQL 生态举个例子
Datadog 之前有一个工作,他们在 PostgreSQL 上实现了一个扩展叫作 pg_tracing https://github.com/DataDog/pg_tracing
通过使用 PostgreSQL 的一些扩展点
- post_parse_analyze_hook
- planner_hook
- ExecutorStart_hook
- ExecutorRun_hook
- ExecutorFinish_hook
- ExecutorEnd_hook
- ProcessUtility_hook
- xact_callback
然后配合一些环形缓冲区和共享内存,就可以在数据库层面上实现一个 tracing 的功能了,这样我们就可以将 PostgreSQL 接入到 OTEL 生态中了。当然这个库的实现里面有不少小技巧,改天可以单独写个文章来聊聊
MySQL 虽然内部的实现是一坨,但是我想如果要在 MySQL 上实现类似的功能应该工作量也不会太大,
最终的效果如下所示
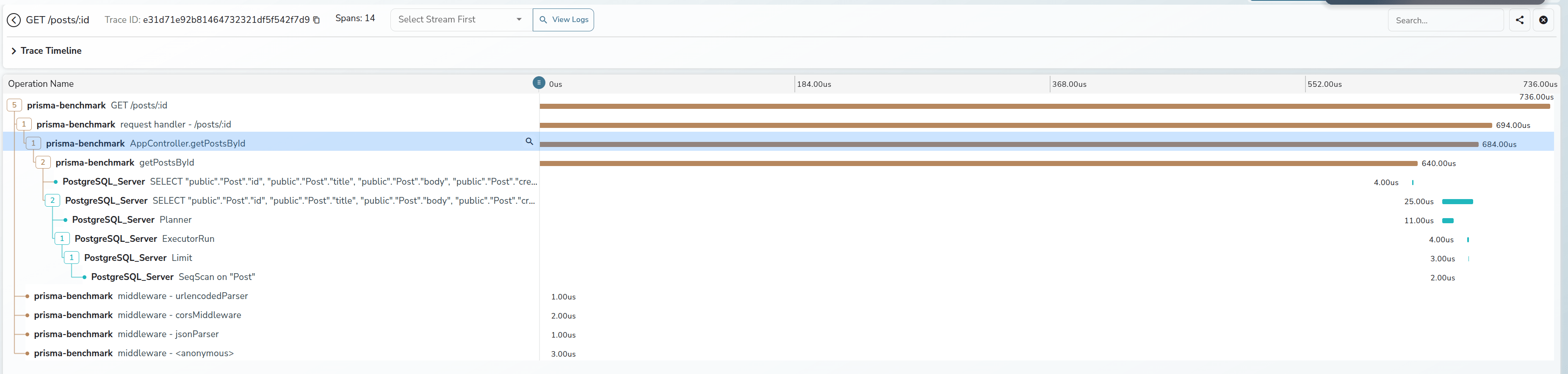
差不多就这样
总结
大家都在写各种 AI/Agent 的文章的时候,我还在搞点这种 old school 的东西。恍惚间看到我的前方有一个巨大的风车。But anyway, 我喜欢这些东西, 这就够了
祝大家看的开心。






